Agentic AI Mathematical Optimization Assistant
Contributors:
Yara Alsinan
https://www.linkedin.com/in/yara-alsinan-1aa305212/
Reece Wooten
https://www.linkedin.com/in/reece-wooten-a82373b4/
¶ AMOA
¶ 1. Roadmap Overview
¶ Agentic AI Mathematical Optimization Assistant (AMOA):
The Agentic AI Mathematical Optimization Assistant: Mathematical optimization applications can be very complicated; the input data is usually vast and complex, the scenario management is cumbersome to keep track of and compare, and the typical workday is only 8-9 hours. Agentic AI Mathematical Optimization Assistant (AMOA) aims to automatically manage this workflow by managing data integrity and update frequency, running sensitivity analysis by using the optimizer based on the latest input data forecasts, and generating comparison reports on substantive results for humans to review and discuss. The technology's primary purpose is to control a set of software procedures, data, and ultimately analysis for human to review during their working hours.
¶ Technology Overview:
The Agentic AI Mathematical Optimization Assistant (AMOA) fuses an agentic AI layer with a mathematical optimization tool suite, enabled through a user-friendly interface that maximizes model transparency. The AI layer handles intent capture, planning, and tool use and translates business requirements into multi-step workflows required for the optimization process. The Optimization layer turns the provided data into optimized decisions with a broad range of sensitivities. Results then flow back to the AI, which then converts that data into domain-specific and human-readable decision-making frameworks. Users will then work through the user interfaces to ensure they understand how the system arrived at its decisions.
¶ Technology Timeline:
The roadmap can progress in parallel workstreams primarily around AI, Optimization, and user interface development. A small proof of concept would be developed for a simple industry standard benchmark model, like the traveling salesman. Here, we can develop the frameworks for how the AI, optimization model, and user interface will need to work together to meet the overall technology system requirements and objectives in a relatively low-stakes environment. Once the proof of concept has been completed, we can start commercializing each workstream. The AI model workstream will start designing specialized agents for each agentic task, and start managing and designing the workflows required for the system. The Optimization workstream will create modular components for each one of its mathematical optimizers it wants to integrate into the AMOA system. Then the user interface workstream will work with the end users to define what are the best interfaces they will need to connect to the AMOA system. As the solution matures, we can continue to add and improve each workstream independently to ensure the AMOA system evolves with business needs.
¶ 2. Design Structure Matrix (DSM) Allocation
¶ 3. Roadmap Model using OPM
¶ 4. Figures of Merit (FOM)
| FOM | Definition | Formula andUnit | Trends (dFOM/dt) |
| Objective Improvement (OBJ_Improvement) | The primary figure of merit (FOM) for AMOA would be the improvement in the objective function actually materialized in business decision-making. This improvement could have a proxy in industry benchmarks; there are a number of academic problems, like the traveling salesman problem, that are used to test the quality and speed of new optimization algorithms. While AMOA doesn’t propose a new optimization algorithm, it can leverage these benchmarks to understand the coverage of sensitivity scenarios. |
OBJ_Improvement = OBJ_ScenarioCase – OBJ_BaseCase Unit: Same as objective function (e.g., cost savings [$], efficiency [%]) |
Expected to increase over time as the AI assistant learns with more data, scenarios, and operations conducted. (s-curve) |
| Cost (C_total) | The model would be deployed for business decision-making, so we would also have to keep track of the cost: |
C_total = CS_size × C Unit: [$] |
Expected to increase exponentially over time until it reaches an asymptote. |
| Explainability (EXP_Score) | This measure is the ability of the AI to accurately explain the model's results to the user. Either through report generation or prompting. |
EXP_Score = R_expected – R_actual Unit: Quality difference score (0–1 or % scale from surveys/feedback) |
Generative AI is typically benchmarked against a set of benchmarks ranging from math tests, software tests, and chat quality and reasoning tests. Since Explainability is closely related to chat quality and reasoning, we will be using/modifying those tests to evaluate AMOAs' performance in this FOM. We expect that as the model gets more training data, specifically for mathematical optimization analysis, this performance will improve over time. |
| Extendability (EXT) | This measure is the ability of the system to extend or add to its existing architecture. For example, a vendor solution might be difficult to modify or extend since it's locked behind proprietary software, while an in house built solution would be easier to extend its architecture to new technologies. | Measured as an index from 0-100 (unit less): It combines number of domains, configurability, and integrated APIs | Qualitatively, EXT follows an S-curve. In the first 1–2 years, AMOA is tailored to one or two flagship use cases, and each new domain still needs a lot of custom work (EXT ~ 10–30). Between ~2–5 years, shared abstractions for scenarios, model metadata, solvers, and XAI start to solidify; the time to onboard a new domain drops from months to weeks, and EXT climbs quickly into the 50–70 range. Beyond ~5 years, most strategic domains and connectors are in place; extending to new domains becomes largely configuration-driven and can often be handled by partner teams using SDKs and templates, so EXT gradually levels off toward 90+ while the marginal cost of each additional extension continues to fall. |
¶ Trends (dFOM/dt):
¶ Objective Improvement:
- The objective improvement FOM trend over time is expected to emulate an s-curve. This is because agentic AI assistants (similar to AMOA) have exhibited slow gains in terms of objective improvement (ex. Efficiency, savings, cases optimized) during the early periods. Since then, objective improvement has been seeing a rapid mid-period rise, particularly during 2021-2025, that is very clear and tangible to all stakeholders and end users. Given that reports indicate that we are still in the mid period, objective improvement is expected to approach saturation and level-off in several years, once it reaches late-time.
- The s-curve can be modeled with the following equation:

Where:
Objmax = maximum objective improvement, which can either be the best-known or proven optimum solution. It represents the FOM’s ceiling.
t = time
t0 = time inflection point, which is where growth is fastest
k = the growth rate constant, which represents the steepness of the improvement. It determines how fast the FOM improves over time.
- k is assumed to be = 0.8
- This is because optimization AI can cut large inefficiencies or enhance metrics quickly at first, showing fast gains in objective improvement once the technology takes off and starts learning user preferences, which is in the mid-period.
- After that, it starts to slightly slow down as it approaches the optimal case.
- A k around 0.8 represents that trend which showcases rapid improvement, but not excessive to the point that it reaches instant saturation.
- Now that the equation has been established, the change of objective improvement over time can be represented by the derivative:

¶ Cost:
- Cost is expected to rapidly increase, as indicated by training costs of AI models over time.
| Year | Model Name | Model Creators/Contributors |
Training Cost (USD) |
|
| Raw Data | Predicted Data | |||
| 2017 | Transformer | $930 | $1,180 | |
| 2018 | BERT-Large | $3,288 | $8,719 | |
| 2019 | RoBERTa Large | Meta | $160,018 | $64,426 |
| 2020 | GPT-3 175B (davinci) | OpenAI | $4,324,883 | $476,046 |
| 2021 | Megatron-Turing NLG 530B | Microsoft/NVIDIA | $6,405,653 | $3,517,530 |
| 2022 | PaLM (540B) | $12,389,056 | $25,991,230 | |
| 2023 | Gemini Ultra | $191,400,000 | $192,050,654 | |

- In the table and graph we have above, training costs of major AI models ballooned over time, multiplying from $930 to $191 million – around 2 x 10^5 increase in just 6 years. This indicates that AMOA’s cost FOM could follow the same trend and grow exponentially, expressed by:

Where:
Ctotal(t) = total cost at time t
C0 = baseline cost in 2017
b = growth constant (approximated to be around ~2 based on the dataset)
t0 = reference year (2017 based on the dataset)
t = time
so,

Now that the equation has been established, the change of cost over time can be represented by:

Which means that the rate of change of total cost is proportional to the instantaneous cost, following an exponential growth trend. This signifies the steep increase in total cost over time, including compute cost. However, as an agentic AI assistant, AMOA’s total cost is expected to plateau as objective improvement, model reuse, and automation increases over time, achieving higher cost efficiency. Thus, total cost is expected to transition to an s-curve once that cost efficiency is reached.
¶ Explainability:
- Explainability’s trend is expected to follow an s-shape curve, as it increases slowly at the early stages of the AI assistant’s development. Based on AI models and languages, the middle period sees a fast growth and increase in explainability, which is eventually expected to asymptote towards a maximum value.
- The s-curve can be modeled with the following equation:

Where:
Expmax = maximum explainability attainable, which is unitless
t = time
t0 = time inflection point, which is where explainability growth is fastest
k = growth steepness constant
- Now that the equation has been established, the change of explainability over time can be represented by:

- To find k, peak rate is taken at t = t0:

- Based on Stanford HAI, the multimodal understanding and reasoning (MMMU) AI index shows an 18.8 percentage point increase between 2023 and 2024 on difficult benchmarks. Hence, we will utilize the MMMU increase as a proxy for explainability improvement. This, combined with assuming that Expmax = 1 yields:

- Hence, k = 0.75 1/yr, and the final derivative can be expressed as:

¶ Resources:
https://www.wsj.com/articles/ai-agents-arrive-at-citi-60a3559d?utm_source=chatgpt.com
https://market.us/report/agentic-ai-in-digital-engineering-market/#utm_source=chatgpt.com
https://www.visualcapitalist.com/training-costs-of-ai-models-over-time/?utm_source=chatgpt.com
¶ 5. Alignment of Strategic Drivers: FOM Targets
| Strategic Driver | Alignment and Targets |
| To develop an Agentic AI specialized model that delivers superior optimization and robustness across domains, enhancing business decision-making, positioning AMOA as a benchmark for reliability and precision. | The AMOA technology roadmap will target a 25% increase in objective improvement and a 60 in intelligence index while ensuring accuracy and consistency through enhanced training data diversity, adaptive evaluation metrics, and continuous learning integration. This driver is fully aligned with AMOA's R&D direction. |
| To achieve cost-efficient intelligence delivery that maximizes model performance while optimizing operational costs. | The roadmap will prioritize algorithmic efficiency and capitalize on existing models, aiming to lower specialized training and inference costs by 50% while maintaining near-frontier improvement and accuracy. This aligns with AMOA's vision of scalable, sustainable AI solutions. |
|
To enhance model explainability and interpretability to strengthen user trust and regulatory readiness, ensuring AI-driven decisions are transparent and auditable.
|
Over time, AMOA aims to enhance and integrate another layer of explainable AI frameworks and transparency modules to provide traceable reasoning outputs for >90% of decisions in a sensitivity analysis. This driver is aligned and currently under prototype testing. |
| To expand accessibility and scalability, democratizing advanced AI capabilities across industries and expertise levels. | The roadmap will enable simplified deployment and adoption through prioritizing intuitive interfaces, modular APIs, and cloud-based options, aiming to reduce integration time by 45% and increase adoption in non-technical sectors. This driver is aligned with AMOA's market expansion goals. |
These strategic drivers link AMOA’s market ambitions with its technology roadmap and development plan, ensuring that each R&D initiative supports the AI assistant’s growth and market distinction.
¶ 6. Positioning of Organization vs. Competition: FOM charts

The agentic index shown here represents an FOM that quantifies agentic performance and capabilities. This includes how well a model performs in an autonomous, reasoning-driven scenario. It is essentially a composite figure that combines multiple aspects, aligned with the Objective Improvement FOM in AMOA’s context, highlighting goal optimization. The current leading models span a range of 55-60, which exemplify the highest levels of autonomous reasoning and optimization performances. As a specialized model, AMOA aims to target an ambitious but realistic index in the high range (around 55) but with improved explainability, accessibility, and cost efficiency, allowing it to occupy an important and distinctive space among its competitors.
Cost Efficiency:

- This chart represents the cost to run the evaluations in the artificial analysis intelligence index; in other words, it plots the AI systems’ performance (intelligence) relative to the inference cost ($). The top left quadrant represents the Pareto-optimal region which houses high intelligence-low cost models. The Pareto front is dominated by GPT-5 (high), GLM-4.6, Grok 4 Fast, and gpt-oss-20B (high) - all of which display high intelligence but at different cost intervals.
- The Pareto front progresses towards the top-left quadrant over time.
- AMOA’s target position today is around the Pareto front, where it would achieve near-optimal efficiency through a high intelligence index around 60-65 and low cost <$128, placing it in the Pareto-optimal region. Essentially, AMOA aims to advance upwards and towards the left until it crosses the frontier over time.
Speed & Latency:

- This chart represents the model’s efficiency through speed. Namely, it shows the model’s intelligence or performance against the output speed (tokens/sec), where the top right quadrant is the most ideal -high intelligence at a high speed. Following a similar trend to intelligence vs cost, GPT-5 (high), Grok 4 Fast, and gpt-oss-120B (high) represent the Pareto front.
- Interestingly, high intelligence-low cost models like DeepSeek V3.2 Exp are on the low end of output speed, demonstrating the potential tradeoff between cost and speed.
- The Pareto front progresses towards the top-right quadrant over time.
- Since AMOA prioritizes objective improvement, cost, and explainability, speed is important but not a top priority. Hence, its position today sits in a 60-65 intelligence range and 150-200 speed, depicting a balance between high capability and moderate speed. Over time, its goal will be to increase speed and efficiency towards the top-right quadrant as the model trains and learns from the user’s requests.
Summarizing the aforementioned FOMs and market space below:
|
Model |
Intelligence Index |
Cost to Run Intelligence Index (USD) |
Output Speed (M output tokens/s) |
| GPT-5 (high) | 61 | 913 | 169 |
| Grok 4 Fast | 56 | 60 | 205 |
| GLM-4.6 | 47 | 221 | 115 |
| DeepSeek V3.2 | 32 | 41 | 29 |
| gpt-oss-120B | 44 | 75 | 366 |
| gpt-oss-20B (high) | 21 | 52 | 256 |
| AMOA | 60-65 | <128 | 150-200 |
AMOA aims to compete in the upper tier of models in terms of performance metrics, distinguishing itself through cost –as it will mostly depend on cost of compute and training the specialized model-, explainability, and transparency to enhance accessibility. Therefore, compared to the data presented in the graphs and the summary table above, AMOA will balance high agentic intelligence with optimized cost, latency, and enhanced explainability. This would look like a model that is positioned below GPT-5 in terms of intelligence, but above GPT-5 in terms of efficiency and cost-effectiveness.
¶ 7. Technical Model: Morphological Matrix and Tradespace
The four figures of merits for AMOA are Objective function improvement, cost, explainability, and extendibility. Other than costs, the data required to measure these FOMs will likely come from company confidential datasets that can estimate how much improvement they see from optimization modeling, how intuitive the results are for their users, and how easy it is to extend the architectures of these models to leverage future technology. So instead of using raw data to evaluate Objective function improvement, explainability, and extendibility, we will use relative figure of merit deltas as an approximation of performance. While the magnitude of the figure of merits won’t have a meaningful interpretation, they are meant to compare alternative concepts. For example, an optimization model could be developed with either an excel template with no approach or solver, just a manually generated model, or one could use a mixed integer program to solve the same problem to optimality, while the true objective function improvement is only known to the companies that produce the results, we can reasonably determine that the global optimal solution from the MIP, will on average be better than the excel template.
Multi-Attribute Utility Model
Using these deltas, we defined a multi attribute utility model, combing our four figures of merit into one utility function. Each attribute utility is defined below. This provides a framework for estimating MAU for AMOA, in practice each parameter of these models would need to be validated with organizational data. For the trade space presented in this section, we calibrated the parameters to get intuitively realistic effects.
- Objective Improvement (OI): Uses a logistic utility function to account for the diminishing returns of more advanced modeling techniques.

- Explainability (XAI): uses a S-curve utility function to account for there being a threshold of adoption at certain levels of explainability, models which are optimal but with low explainability simply won’t’ be used in practice.

- Expendability (EXT): Uses a logistic utility function to account for the diminishing returns of more complex architectures being marginally less extendable than simpler ones.

- Return on Investment (ROI): Uses a logistic utility function to account for the diminishing returns of ROI on more complex models.
We then aggregated these utilities through a weighted product; we chose to do this instead of an additive aggregation because the concepts are a bundle of features from functional blocks. An AMOA system might have really advanced optimization modeling technologies, but without basic reporting or explainability features, the overall technology will have a low utility.

Trade space
Using the multi-attribute utility model, we sampled the available technologies within the functional blocks of AMOA to generate candidate concepts. We leveraged a stratified sampling method to ensure we generated diverse concepts across the four tiers of concepts: Basic, Standard, High, Elite. These tiers relate to the relative complexity, benefit, and cost of each additional feature. For example, excel might be put into a basic tier while a vendor solution might be put into a standard or high tier.
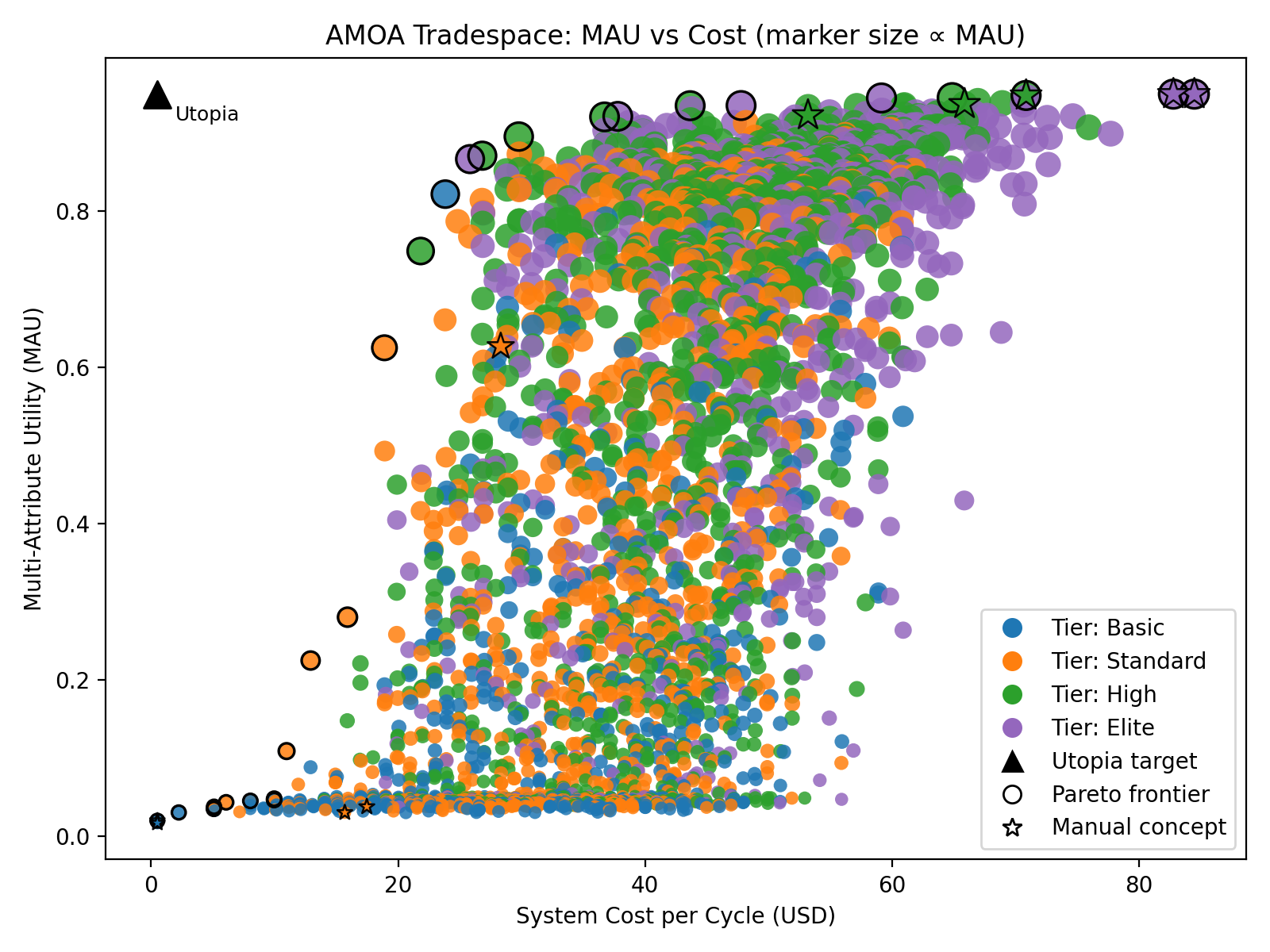
In the trade space figure, we can see how the trade space evolves, the top left is the utopia point, where low cost, and high utility occurs. The chart highlights the pareto front concepts, ranging from basic concepts all the way to elite concepts. Supplemental to the trade space chart, we have attached a table of a sample of the concepts in the pareto front.
|
Functional Block |
Concept 1 Basic | Concept 8 Standard | Concept 12 High | Concept 18 Elite |
|
Scenario generation |
LLM + RAG (citations) | LLM + RAG (citations) | Simulation-based Generator | Simulation-based Generator |
|
Data ingestion & prep |
Feature store + schemas | Feature store + schemas | Contracts + drift detection | Feature store + schemas |
|
Feasibility & QA |
Hard constraint checks only | Rulebook + statistical QA | Counterexample search (+repair) | Counterexample search (+repair) |
|
Model platform |
Proprietary optimization suite (with UI) | Python optimization platform (API + pipelines) | Python modeling toolkit (Pyomo/PuLP) | Enterprise decision platform (multi-model) |
|
Solver & compute |
Open-source MILP (CBC/GLPK) | Commercial MILP + autoscale | Commercial MILP + autoscale | Open-source MILP (CBC/GLPK) |
|
Orchestration / Agents |
Multi-agent (planner/critic) | Multi-agent (planner/critic) | Multi-agent (planner/critic) | Learned routing/policies |
|
Uncertainty & stress |
Parameter sweeps | Parameter sweeps | Parameter sweeps | Distributional stress testing |
|
Sensitivity/robustness |
One-at-a-time (OAT) | One-at-a-time (OAT) | Sobol / global sensitivity | Sobol / global sensitivity |
|
Human-in-the-loop (HITL) |
Optional reviewer | Optional reviewer | Optional reviewer | Optional reviewer |
|
Reporting / XAI |
Executive brief only | Decision cards (+citations/caveats) | Lineage + rationale | Add counterfactuals |
|
Audit & compliance |
Immutable logs + versions | Full audit trail | Full audit trail | Immutable logs + versions |
|
Monitoring & observability |
Solve time only | Solve time only | KPIs + drift + cost | Full SLOs + guardrails |
|
Deployment |
Single cluster | K8s batch (blue/green) | K8s batch (blue/green) | Serverless + guardrails |
|
Functional Block |
FOM |
Concept 1 Basic |
Concept 8 Standard |
Concept 12 High |
Concept 18 Elite |
|
Scenario generation |
delta_OI |
-0.08 |
-0.08 |
1.22 |
1.22 |
| delta_XAI |
-0.05 |
-0.05 |
0.03 |
0.03 |
|
| delta_EXT |
-0.06 |
-0.06 |
0.18 |
0.18 |
|
| delta_SC |
0 |
0 |
0.036 |
0.036 |
|
|
Data ingestion & prep |
delta_OI |
-0.08 |
-0.08 |
0.45 |
-0.08 |
| delta_XAI |
-0.05 |
-0.05 |
0.1 |
-0.05 |
|
| delta_EXT |
-0.06 |
-0.06 |
0.09 |
-0.06 |
|
| delta_SC |
0 |
0 |
5.0144 |
0 |
|
|
Feasibility & QA |
delta_OI |
-0.5 |
-0.08 |
0.92 |
0.92 |
| delta_XAI |
-0.2 |
-0.05 |
0.23 |
0.23 |
|
| delta_EXT |
-0.28 |
-0.06 |
0.18 |
0.18 |
|
| delta_SC |
-0.0072 |
0 |
5.0288 |
5.0288 |
|
|
Model platform |
delta_OI |
0.02 |
0.7 |
0.5 |
0.97 |
| delta_XAI |
-0.05 |
0.15 |
0.11 |
0.22 |
|
| delta_EXT |
-0.06 |
0.09 |
0.09 |
0.18 |
|
| delta_SC |
4.0216 |
5.0252 |
3.018 |
6.036 |
|
|
Solver & compute |
delta_OI |
-0.4 |
-0.08 |
-0.08 |
-0.4 |
| delta_XAI |
-0.15 |
-0.05 |
-0.05 |
-0.15 |
|
| delta_EXT |
-0.28 |
-0.06 |
-0.06 |
-0.28 |
|
| delta_SC |
-0.0036 |
0 |
0 |
-0.0036 |
|
|
Orchestration / Agents |
delta_OI |
-0.08 |
-0.08 |
-0.08 |
0.82 |
| delta_XAI |
-0.05 |
-0.05 |
-0.05 |
0.15 |
|
| delta_EXT |
-0.06 |
-0.06 |
-0.06 |
0.18 |
|
| delta_SC |
0 |
0 |
0 |
5.036 |
|
|
Uncertainty & stress |
delta_OI |
-0.08 |
-0.08 |
-0.08 |
0.82 |
| delta_XAI |
-0.05 |
-0.05 |
-0.05 |
0.12 |
|
| delta_EXT |
-0.06 |
-0.06 |
-0.06 |
0.18 |
|
| delta_SC |
0 |
0 |
0 |
5.0288 |
|
|
Sensitivity/robustness |
delta_OI |
-0.4 |
-0.4 |
0.35 |
0.35 |
| delta_XAI |
-0.15 |
-0.15 |
0.08 |
0.08 |
|
| delta_EXT |
-0.28 |
-0.28 |
0.09 |
0.09 |
|
| delta_SC |
-0.0036 |
-0.0036 |
3.0144 |
3.0144 |
|
|
Human-in-the-loop (HITL) |
delta_OI |
-0.4 |
-0.4 |
-0.4 |
-0.4 |
| delta_XAI |
-0.12 |
-0.12 |
-0.12 |
-0.12 |
|
| delta_EXT |
-0.28 |
-0.28 |
-0.28 |
-0.28 |
|
| delta_SC |
0 |
0 |
0 |
0 |
|
|
Reporting / XAI |
delta_OI |
-0.4 |
0.32 |
-0.08 |
0.25 |
| delta_XAI |
-0.35 |
0.33 |
-0.05 |
0.25 |
|
| delta_EXT |
-0.28 |
0.18 |
-0.06 |
0.09 |
|
| delta_SC |
-2.0108 |
2.0144 |
0 |
2.0108 |
|
|
Audit & compliance |
delta_OI |
-0.08 |
0.15 |
0.15 |
-0.08 |
| delta_XAI |
-0.05 |
0.25 |
0.25 |
-0.05 |
|
| delta_EXT |
-0.06 |
0.09 |
0.09 |
-0.06 |
|
| delta_SC |
0 |
4.0108 |
4.0108 |
0 |
|
|
Monitoring & observability |
delta_OI |
-0.4 |
-0.4 |
-0.08 |
0.52 |
| delta_XAI |
-0.15 |
-0.15 |
-0.05 |
0.14 |
|
| delta_EXT |
-0.28 |
-0.28 |
-0.06 |
0.18 |
|
| delta_SC |
-2.0108 |
-2.0108 |
0 |
4.0288 |
|
|
Deployment |
delta_OI |
-0.4 |
-0.08 |
-0.08 |
0.47 |
| delta_XAI |
-0.15 |
-0.05 |
-0.05 |
0.11 |
|
| delta_EXT |
-0.28 |
-0.06 |
-0.06 |
0.18 |
|
| delta_SC |
-0.0072 |
0 |
0 |
6.0288 |
Generative AI Usage: Chat GPT 5 thinking and Chat GPT 5 Codex-High was used to formulate and develop the trade space analysis in python. Analysis and validation of the trade space was human generated.
¶ 8. Financial Model: Technology Value (𝛥NPV)
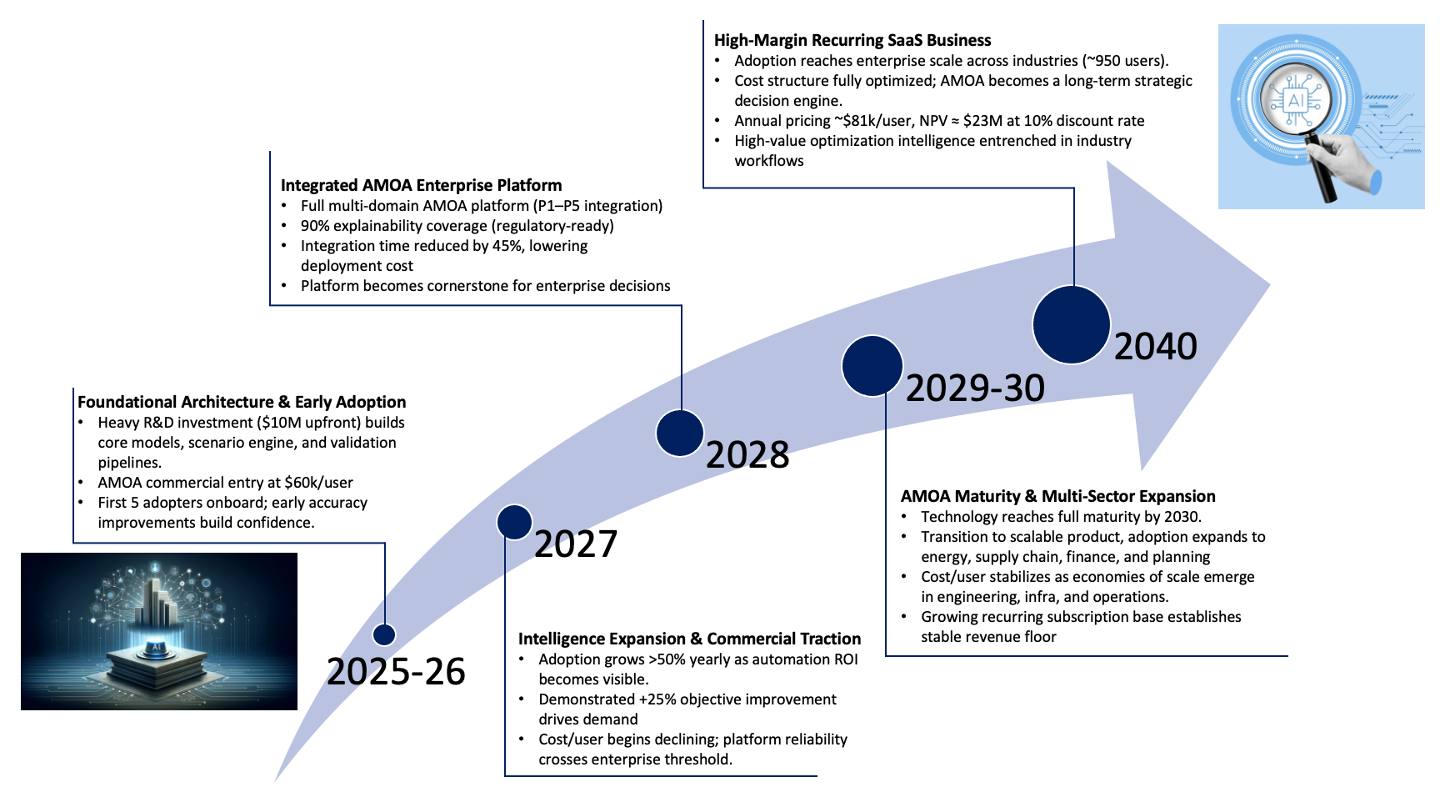
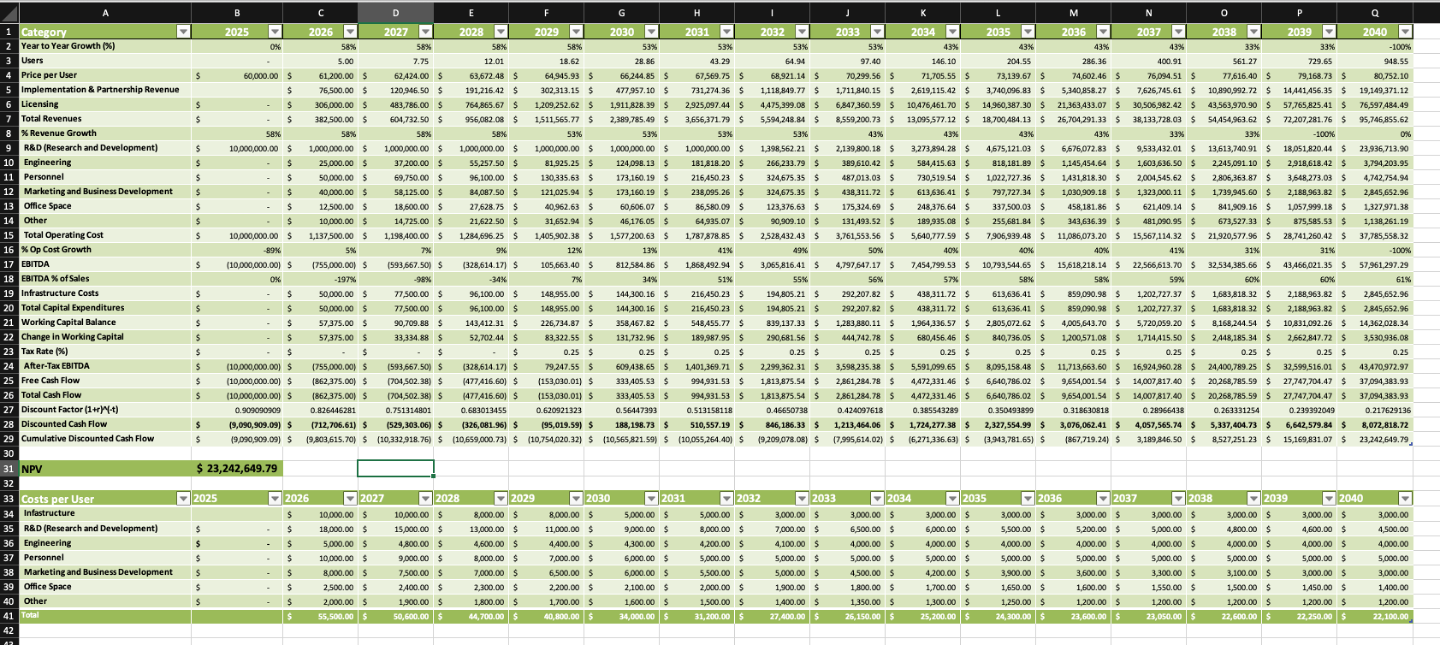
This NPV analysis models AMOA as a high-value business software solution that replaces analyst positions within companies. The pricing starts at $60,000 per user in 2026 and increases by about 2% annually, reaching approximately $81,000 per user by 2040. User growth begins with 5 early adopters in 2026 and expands rapidly at around 58% per year initially, then slows to the mid-30% range in later years, reaching about 950 users by 2040.
Revenue comes from two sources: recurring subscription fees and one-time implementation and partnership fees, with subscriptions becoming the dominant revenue stream as the product matures. On the cost side, the model includes a $10 million upfront research and development investment in 2025, followed by ongoing costs for R&D, engineering, staffing, marketing, office space, and operations. These costs are largely tied to the number of users and decrease on a per-user basis over time as the platform scales up. Infrastructure spending is concentrated in the early years and then decreases, while working capital needs grow with revenue. Taxes only apply once AMOA becomes profitable.
Using a 10% discount rate over the 2025–2040 period, the base case produces a net present value of approximately $23 million. This indicates that while AMOA requires significant upfront investment, it creates substantial value once user adoption grows and profit margins improve through economies of scale.
¶ 9. List of R&D Projects and Prototypes
P1. Agentic Workflow Orchestrator v1 (Foundational)
Priority: Very High (Phase 1 - 0-12 months)
Technical description
Build the core agentic planner that:
- Interprets user intent
- Selects and calls optimization models & tools
- Executes multi-step workflows (data prep to solve to sensitivities to reporting),
- Handles failures/retries and basic tool selection.
Initial version can assume 1-2 optimization domains and a small set of tools (e.g., “run base model”, “run sensitivity scenario”, “compare cases”).
Effects on figures of merit
- OI: ++: Enables complex multi-step exploration that humans rarely do manually.
- COST: +: Automates repetitive workflows, reducing analyst time per scenario.
- XAI: 0/+: If you log the plan and steps, it slightly improves transparency.
- EXT: ++: Orchestrator is the backbone for plugging in more tools/models later.
Technical effects
- Establishes the control layer for AMOA (policies, tool interfaces, error handling).
- Forces clear tool contracts and standard I/O schemas between AI and optimizers.
- Provides telemetry data (what plans work/ fail) for later learning.
Business effects
- Faster scenario turnaround (days to hours; hours to minutes).
- More consistent workflows across analysts/teams.
- Clear early demo value: “Ask AMOA to analyze X; it automatically runs several cases and summarizes results.”
Relative risk score
- Risk: 3/5 (medium)
- Orchestration logic is non-trivial but uses known patterns (tool calling, planning).
- Main risk is complexity creep; mitigated by scoping to 1-2 use cases first.
Estimated cost and timeline
- Timeline: 6-9 months
- Cost: Medium - ~3-5 engineers (AI + optimization + platform) + 1 PM/analyst.
P2. Optimization Abstraction Layer & Model Registry
Priority: Very High (Phase 1 - 0-12 months)
Technical description
Create a uniform abstraction layer over optimization models:
- Standard APIs to “submit_run”, “get_status”, “fetch_results”.
- Model registry with metadata (domain, objective, constraints, inputs/outputs).
- Versioning and configuration management for models and solvers.
Effects on figures of merit
- OI: +: Makes it easier to route problems to the “right” model.
- COST: +: Central control over solver settings to better utilization and batching.
- XAI: +: Clear model metadata supports better explanation and audit.
- EXT: ++: Essential to onboard new models quickly.
Technical effects
- Reduces coupling between AI agents and underlying solver tech.
- Enables A/B testing between models/solver configs.
- Foundation for future “model marketplace” inside AMOA.
Business effects
- Faster onboarding of new optimization problems.
- Lower operational risk (fewer one-off scripts, more standardized services).
- Easier compliance/audit.
Relative risk score
- Risk: 2/5 (low-medium)
- Mostly engineering/plumbing plus good design choices.
Estimated cost and timeline
- Timeline: 6-9 months for initial layer covering 1-3 key models.
- Cost: Medium - 2-3 backend/optimization engineers.
P3. Data Ingestion & Optimization Feature Store
Priority: High (Phase 1-2)
Technical description
Build a data pipeline and feature store specialized for optimization:
- Connect to operational systems (trading, planning, logistics, etc.).
- Normalize entities (assets, products, routes, constraints).
- Maintain “ready-to-solve” data views, including bounds and parameters.
- Store scenario inputs & outputs as first-class objects.
Effects on figures of merit
- OI: ++: Better, cleaner, more timely data to better decisions.
- COST: +: Less manual data prep per run.
- XAI: +: Data lineage improves explainability.
- EXT: +: Makes it easier to add new domains that reuse common data entities.
Technical effects
- Standardizes inputs across models and domains.
- Enables back testing (replay historical scenarios).
- Forms the base for data quality checks & anomaly detection.
Business effects
- Reduces manual data wrangling.
- Increases trust in optimization outputs.
- Enables robust KPIs and post-hoc analysis for decisions.
Relative risk score
- Risk: 3/5 (medium)
- Data integration is messy and domain-specific; complexity depends on legacy systems.
Estimated cost and timeline
- Timeline: 12-24 months to reach a robust, multi-domain store.
- Cost: High - 3-5 data/platform engineers + domain SMEs over time.
P4. Scenario Generation & Experiment Design Engine
Priority: High (Phase 2 - 1-3 years)
Technical description
Develop an engine that automatically proposes and manages scenarios:
- Given a user question, generate a set of structured scenarios.
- Use robust planning principles (e.g., varying key drivers, combining stressors).
- Manage scenario bundles, naming, grouping, and comparison.
Effects on figures of merit
- OI: ++: Encourages broader exploration; uncovers better plans.
- COST: 0/-: More runs may increase compute but can be mitigated with smart pruning.
- XAI: +: Systematically organized scenario sets are easier to explain.
- EXT: +: Reusable scenario patterns across domains.
Technical effects
- Tightly couples to orchestrator (P1) and model registry (P2).
- Requires parameterization of models (which inputs can be perturbed, and how).
- Builds foundation for robust/stochastic optimization later.
Business effects
- Supports strategic questions.
- Enables standardized “playbooks” (e.g., stress test templates).
- Increases perceived intelligence of AMOA.
Relative risk score
- Risk: 3/5 (medium)
- Needs good design to avoid combinatorial explosion of scenarios.
Estimated cost and timeline
- Timeline: 9-15 months for v1 after P1/P2.
- Cost: Medium - 2-3 engineers + 1 ops research SME.
P5. Decision Cards & Explainability (XAI) Framework
Priority: High (Phase 1-2 - early version needed quickly)
Technical description
Create the UI and explanation layer that turns raw optimization outputs into:
- “Decision cards” summarizing key recommendations, trade-offs, and sensitivities.
- Structured narratives: “Because of A, B, and C, we recommend action D.”
- Links to data lineage, constraint binding info, and scenario comparisons.
Effects on figures of merit
- OI: +: Better understanding to better adoption to better realized outcomes.
- COST: +: Reduces back-and-forth explanation cycles.
- XAI: ++: Directly targets explainability.
- EXT: 0/+: A good framework can be reused in new domains.
Technical effects
- Requires rich metadata from models (constraints, duals, binding constraints, etc.).
- Pulls from feature store + orchestration logs.
- Defines a schema for “explanations” that agents can populate.
Business effects
- Critical for trust and adoption: non-technical decision makers can actually use AMOA.
- Helps with regulatory/audit requirements.
- Differentiator vs. black-box “AI optimizer” tools.
Relative risk score
- Risk: 2/5 (low-medium)
- UI + explanation logic is conceptually straightforward; risk is UX quality and domain fit.
Estimated cost and timeline
- Timeline: 6-12 months for meaningful v1.
- Cost: Medium - 2-3 engineers + 1 UX designer + 1 domain expert.
¶ 10. Key Publications, Presentations and Patents
¶ 10.1 Publications & Presentations
- Democratizing Optimization with Generative AI (SSRN 5511218)
Description and relevance:
The paper highlights mathematical optimization as a remarkable, underutilized branch of GenAI when it comes to the nonexpert community. Hence, the paper aims to bridge that gap to increase the understanding and application of optimization and realize the technology’s true potential. This is done by presenting the 4I structure: insight, interpretability, interactivity, and improvisation, principles aiming to make optimization through GenAI more accessible, explainable, and easily usable. Interestingly, it sheds light on the fact that GenAI does not replace optimization, contrary to popular belief. Instead, mathematical optimization remains a powerhouse in reaching optimum results in a business context, and GenAI complements it and enables its application on a larger, more accessible scale. The paper further illustrates the risk of overdependence on GenAI and provides research insights and directions on ensuring fair, ethical utilization. This paper is especially relevant to AMOA because it emphasizes the importance of optimization as an application of GenAI, and aims to make it more accessible and trustworthy to users of all backgrounds. Similarly, AMOA specifically aims to employ mathematical optimization towards achieving highly efficient objective improvement through the use of agentic AI and training a specialized model. Furthermore, the paper places AI optimization in the context of business decision-making, especially by non-experts, which is AMOA’s main purpose and implementation space. Additionally, it highlights the importance of interpretability, explainability, and transparency, all of which are integral aspects and potential FOMs of AMOA.
2. Leveraging Large Language Models for Supply Chain Management Optimization: A Case Study (DOI:10.1007/978-3-031-80775-6_13)
Description and relevance:
This paper explores how LLMs and generative AI can unlock incredible opportunities when deployed in operations by streamlining computation-intensive steps towards optimization. The research shows methods to translate complex mathematical operations into functional code and interpretable results. Interestingly, the paper highlights how LLMs can increase the efficiency and accuracy of traditional solvers. The presented examples support these claims and further show that LLMs have the capacity to provide sound reasoning and interpret complex results. This closely aligns with AMOA’s explainability pillar and places emphasis on agentic AI interactivity. Furthermore, employing an LLM towards specialized training for optimization purposes is similar to AMOA’s development plan. Both the case in the paper and AMOA exemplify AI’s ability to optimize conditions, simplify complex results, and provide practical reasoning for the user. This fits under the accessibility goals as the paper and AMOA exemplify the possibility of onboarding non-experts with guided prompts while enhancing solver rigor.
3. Agentic Workflows Generation Based on Meta-Cognitive Chain-of-Thought Guided Monte Carlo Tree Search (DOI:10.1109/ICNLP65360.2025.11108534)
Description and relevance:
The paper sheds light on the challenge faced by LLMs that, despite their remarkable understanding capabilities, they can fall short on decision-making. With that in mind, recent studies introduce agent-based LLMs. However, these require manual work and because of that, are very complicated and require experts’ input, making them inaccessible. To tackle this issue, the paper introduces a new method that automated generation of LLM workflows through employing a Chain-of-Thought (CoT) reasoning coupled with a Monte Carlo Tree Search (MCTS) optimization. This allows systems to adapt workflows accordingly, enhancing efficiency and performance. The paper presents experimental results which substantiate the proposed approach and hypothesis by demonstrating that they can navigate complex problems and advance automated, multi-agent workflows in diverse areas including industrial, computational, and reasoning fields. This paper’s relevance to AMOA lies in the process it proposes. The approach can be adapted to be applied within AMOA as it receives input, validates, solves, compares sensitivities and provides a brief that navigates practical domains. The paper also highlights that this approach could achieve faster convergence and higher accuracy, which is a top priority for AMOA as a technology and AI agent.
¶ 10.2 Patents
- Multimodal Data Processing System with Joint Optimization of Neural Compression and Enhancement Networks
Patent ID: US 20250307631A1
CPC Codes:
- G06N 3/08 (2023.01)
- G06N 3/0455 (2023.01)
- G06N 3/0495 (2023.01)
Description and relevance:
This patent details a system that processes, compresses, and optimizes multimodal data using trained neural compression and enhancement networks together. This allows all components to undergo optimization at the same time by implementing a loss function that prioritizes balancing the reconstruction quality against a neural enhancement network. The process includes an iterative, agentic feedback loop that ensures sufficiently exploring scenarios and re-optimizing as needed, maintaining data integrity, interpretability, and automation of the workflow, all of which are integral to AMOA’s operations.
It is especially relevant because it places an emphasis on continuously evaluating and analyzing scenarios, in addition to enabling AI-driven data control and reprocessing. In the same vein, AMOA aims to achieve high objective improvement by doing that and exhaustively exploring the sensitivity space to ensure optimization.
2. Artificial Intelligence Based Virtual Agent Trainer
Patent ID: US011270081B2
CPC Codes:
- G06F 40/247
- G06F 40/284
- G06F 40/35
- G06K 9/6257
- G06K 9/6264
- G06N 3/08
- G06N 5/003
- G06N 77005
- G10L 13/00
- G10L 21/18
- G10L 25/30
Description and relevance:
The patent describes a system, process, and product that enhances an AI agent’s communication by having a memory system that stores instructions over uses, working in conjunction with a processor. This AI training method is iterative, where it processes the input data and yields utterances continually to be utilized as training datasets to train and validate the AI model. Notably, it presents recommendations and a maturity assessment based on the verification results, enhancing the accuracy and transparency of the model. This is especially relevant to AMOA as AMOA emphasizes explainability, human-interpretable results, and human interaction. This patent aligns with that as it highlights training and improving agentic dialogue components and auditability/explainability mechanisms. Additionally, the main elements of this patent are a processor for communication and memory for storage – both of which are crucial to AMOA’s function and employment. Over time, and as AMOA receives more instructions, learns, and builds a memory, its objective improvement and optimization results are expected to become more efficient and explainable.
¶ 11. Technology Strategy Statement
Our goal is to build a domain-specialized agentic optimization system that outperforms traditional analytics and generic AI models in objective improvement, explainability, cost efficiency, and extendability with full operational readiness by 2028 and maturity by 2030. In essence, AMOA will combine agentic AI with mathematical optimization, yielding a highly accessible, decision-supporting tool. To achieve AMOA's performance targets of >25% objective improvement, a 50% reduction in specialized training and inference costs, increase explainability to >90% coverage, and enhance extendability, we will invest in five R&D projects.
The first project is the Agentic Workflow Orchestrator, which will deliver the core functional agentic planning system by the end of 2026, capable of executing multi-step optimization workflows and automatically running cases and generating sensitivity analyses. This orchestrator provides the enabling control layer required for enhancing objective improvement, reducing cost, and ensuring the system’s long-term extendability.
The second project is the Optimization Abstraction Layer & Model Registry, which will provide a uniform abstraction layer, version and configuration management, and model metadata by the end of 2026. This layer is essential for model auditability, explainability, and rapid onboarding of new optimization domains, increasing extendability.
The third project is the Data Ingestion & Optimization Feature Store, which will standardize data ingestion and scenario storage by 2027, enabling higher-quality optimization inputs and specifically enhancing objective improvement and cost efficiency.
The fourth project is the Scenario Generation & Experiment Design Engine, with a first operational prototype by 2027, enabling automatic scenario bundles and management, and robust planning workflows. This project directly supports AMOA’s objective improvement and considerably enhances explainability and extendability goals.
The fifth project is the Decision Cards & Explainability Framework, which will be deployed in stages from 2026–2028, delivering interpretable decision cards, constraint-binding rationale, data lineage, and auditable reasoning covering more than 90% of model-driven recommendations, directly targeting explainability.
Together, these technologies will enable AMOA to become a highly accessible optimization assistant with frontier-level performance, explainability, and extendability, delivered at significantly reduced operational cost. The swoosh chart summarizes the maturity path of these capabilities through 2025–2040.